AI Demystified: How It Works Without the Complex Math - Part 2

Continuation of the AI Demystified: How It Works Without the Complex Math - Part 1.
In this blog post, we will exploring evolution and functionality of generative AI models.
Generative AI
Generative AI refers to models that create entirely new content—whether generating images from scratch, responding to user prompts, or producing original text. Beneath their impressive capabilities, these systems are still neural networks built from the same fundamental components we've explored: nodes, weights, attention mechanisms, and training through gradient descent. However, they've been specifically designed and trained for creation rather than just classification or prediction. We will be focusing on three kinds of generative AI models
- Generative Adversarial Networks (GANs) - Primarily used for image generation. These work like an art forger competing against an art detective: one network creates fake images while another tries to detect them, forcing both to get better until the fakes become indistinguishable from real photos.
- Diffusion Models - Also primarily used for image generation. These learn to gradually transform random noise into coherent images, like watching a photograph slowly emerge from static—the process that powers tools like DALL-E and Midjourney.
- Large Language Models (LLMs) - Primarily used as conversational agents and text generators. These models predict and generate human-like text by learning patterns from vast amounts of written content, enabling everything from chatbots to creative writing assistants.
Generative Adversarial Networks (GANs)
GANs are pattern generators, they memorize patterns and structures not specific facts, they are good for creating realistic looking content in a learned style but they can't handle specific factual requests or complex instructions.
GANs have two parts, Generator and Discriminator.
- Generator generates based on random noise which is feed as input.
- During training, Discriminator identifies whether output generated by generator is real or fake based on the training data.
Discriminator during the training phase acts as a feedback mechanism to fine tune generators parameters to produce optimal results. Once the training is complete, discriminator is usually discarded and generator is the only entity needed for making new content.
Training this model looks something like captured below
- Generator creates fake data from random noise which is provided as input.
- Discriminator sees both real data (from training set) and fake data (from generator).
- Discriminator makes judgements on both real and fake samples.
- Discriminator learns, when it makes mistakes, for example: calls a real data "fake", updates the parameters (weights, bias etc.,) to better recognize real images.
- Generator learns, when discriminator correctly identifies its output as fake, generator updates its parameters (weights, bias etc.,) to be more convincing.
- This feedback process continues until, they attain "Nash equilibrium" where
- Generator fools discriminator - ~50% of the time
- Discriminator catches fake ~50% of the time
- Neither can improve further without the other getting better too.
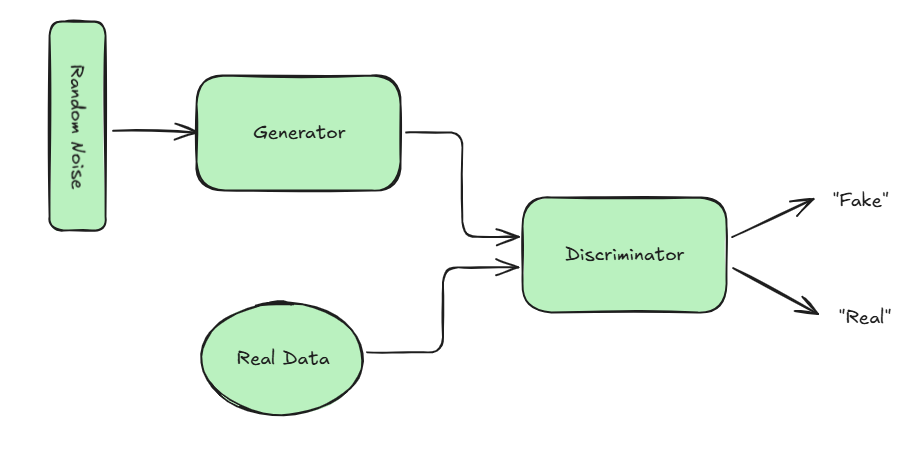
Let's walk through an example of GANs generating images, which will help make these abstract concepts more concrete.
Training:
- GANs learn from a fixed dataset (like 50,000 face photos you give them) and they never access new images from the web.
- They learn visual patterns and structures from this training data, for example: "Human faces usually have eyes above the nose, specific proportions, certain lighting patterns, skin textures..."
During Generation (after training):
- GANs use only what they learned during training—no web scanning, no database lookups, no external access. They generate based purely on learned visual patterns.
- When a user requests a face image, random noise
[0.23, -0.45, 0.67, ...]is generated internally and fed as input. - This random noise translates to visual instructions like "Use pattern A for eye shape, pattern C for nose structure, pattern B for lighting."
- Learned pattern: "Round eyes + straight nose + soft lighting"
- Random noise decides: Use specific eye curvature, particular nose width, certain shadow placement
- Output: A unique face image with those characteristics
- Every time a face image is requested, different random noise values create completely different facial features and appearances.
The Challenge: What if the user wants a specific type of face—say, "smiling woman with brown hair"? That's where Conditional GANs come into play.
Conditional GANs add control to pattern selection. Instead of just learning visual patterns, they learn labeled visual patterns during training.
Conditional GAN Example:
- Input: Random noise
[0.8, -0.3, 0.6, ...] - Label: "SMILING WOMAN"
- Noise
0.8→ Choose "upturned mouth" pattern - Noise
-0.3→ Choose "feminine facial structure" - Noise
0.6→ Choose "brown hair texture" pattern - Output: Image of a smiling woman with brown hair
- Noise
- Same noise with different label: "SERIOUS MAN"
- Output: Image of a serious-looking man with different features entirely
The same mathematical noise creates completely different images depending on the conditioning label provided.
Diffusion Model
Diffusion models work fundamentally differently from GANs—instead of competing networks, they use a process that mimics how ink diffuses through water, but in reverse.
The Core Concept: Think of diffusion models like learning to "un-scramble" images. During training, they take real images and gradually add random noise until the image becomes pure static. Then they learn to reverse this process—turning noise back into coherent images.
Training Process:
- Forward Diffusion: Take a real photo → gradually add noise over many steps → end up with pure random noise
- Learning Reverse: Train a neural network to predict and remove the noise at each step
- Practice: The model learns "if I see this noisy mess, the previous step probably looked like this"
Generation Process:
- Start with pure random noise (like TV static)
- The trained model gradually removes noise over many steps (often 50-1000 steps)
- Each step makes the image slightly clearer and more coherent
- Final result: A completely new, realistic image
Why Diffusion Models Excel:
- Stability: Unlike GANs' competitive training, diffusion models have stable, predictable training
- Quality: They often produce higher-quality, more detailed images
- Control: Easy to guide the generation process with text prompts
- Diversity: Can generate incredibly varied outputs
Real-World Example: When you type "a sunset over mountains" in DALL-E or Midjourney:
- Starts with noise conditioned on your text prompt
- Gradually "denoises" the image while keeping your prompt in mind
- Each step reveals more sunset and mountain features
- After many steps: A unique sunset mountain scene
This is why diffusion models power most modern AI art generators—they're more reliable and controllable than GANs while producing stunning results.
Large Language Models (LLMs)
The AI assistants you interact with daily— OpenAI's ChatGPT, Google's Gemini, Anthropic's Claude—all share the same foundational technology: advanced neural networks built on something called the Transformer architecture. Introduced in 2017, transformers represented a breakthrough in how neural networks process information, enabling much more effective and parallel processing than previous approaches. Now that we understand how basic neural networks learn and adapt, let's explore what makes transformers so special and how they evolved into the powerful language models that can write, reason, and converse with remarkable sophistication.
Before transformers revolutionized AI, researchers used Recurrent Neural Networks (RNNs) to process text. Think of RNNs like reading a book word by word, where each word's understanding depends on remembering what came before. The network processes "The cat sat on the..." and by the time it gets to "mat," it needs to remember "cat" was the subject. However, RNNs had severe limitations: they could only hold small amounts of context in memory, were incredibly slow to train (since each word had to be processed sequentially), and struggled with long-distance relationships in text. These constraints made them impractical for complex real-world applications.
Transformers solved these problems with a fundamentally different approach. Instead of processing words one by one, transformers can look at entire sentences simultaneously there by facilitating parallel processing and contextual understanding of the input.
Lets walk through the steps on a high level which will help us understand transformer architecture better
1. Breaking Down Your Words: Tokenization
First, the AI doesn't see words the way you do. Instead, it breaks your sentence into tokens – think of these as the AI's vocabulary units. Sometimes a token is a whole word like "cat," but it might also be part of a word like "un-" or "-ing," or even punctuation marks.
"The cat sat on the mat" might become tokens like: ["The", "cat", "sat", "on", "the", "mat"]
This process is like having a universal translator who first breaks down your sentence into standardized building blocks that the AI can work with.
2. From Tokens to Numbers: Vector Conversion
Here's where it gets interesting. Computers can't actually understand words – they only understand numbers. So each token gets converted into a vector – essentially a long list of numbers (typically hundreds of dimensions).
Think of it like assigning a unique fingerprint made of numbers to each word. "Cat" might become something like [0.2, -0.1, 0.8, 0.3, ...] with hundreds of numbers. These aren't random – they're learned patterns that capture the meaning and relationships of words.
3. Mapping Meaning: Token Embeddings
Now comes the beautiful part. All these number-fingerprints get plotted in what we call an embedding space – imagine a vast, multi-dimensional map where similar words cluster together.
In this space, "cat" and "dog" would be close neighbors because they're both pets. "King" and "queen" would be near each other, and amazingly, the distance and direction between "man→woman" would be similar to "king→queen." The AI has learned to organize the entire world of language into a geometric landscape of meaning.
4. Understanding Position: Positional Embeddings
But wait – word order matters! "The cat chased the dog" means something very different from "The dog chased the cat." So the AI adds positional information to each word's vector, essentially giving each token a sense of where it sits in the sentence.
Think of it like adding GPS coordinates to each word – not just what the word means, but where it appears in the sequence. This helps the AI understand that in "I saw her duck," the position tells us whether we're talking about seeing someone's pet bird or watching someone quickly bend down.
5. The Magic of Self-Attention: Connecting the Dots
Here's where transformers truly shine. The self-attention mechanism is like having each word in your sentence have a conversation with every other word, figuring out which words are most important to pay attention to.
When processing "The cat that I adopted yesterday is sleeping," the AI figures out that "cat" and "sleeping" are strongly connected, even though they're far apart in the sentence. It's like each word asking, "Who in this sentence is most relevant to understanding me?"
This happens in parallel for all words simultaneously – imagine everyone in a room having multiple conversations at once, but somehow keeping track of all the important connections.
6. Making Predictions: Feed-Forward Processing
After all this attention and relationship-mapping, the information flows through feed-forward networks – think of these as decision-making layers that process all the gathered information.
But here's a key clarification: these networks don't just output "the next possible words with probability." Instead, they transform and refine the information at each position, preparing it for the final prediction step. It's more like a series of thoughtful analysts, each adding their expertise to understand what should come next.
7. The Final Prediction: What Comes Next?
Only at the very end does the model make its prediction about the next token. It looks at all the processed information and generates a probability distribution over its entire vocabulary. Maybe there's a 30% chance the next word is "on," 25% chance it's "in," 15% chance it's "under," and so on.
The model then selects from these possibilities (not always the most likely one, which is why AI can be creative and varied in its responses).
8. Back to Human Language: Detokenization
Finally, the selected tokens get converted back into readable text through detokenization – essentially the reverse of step 1. Those number-tokens become words and sentences that you can understand.
What makes this process remarkable is that it all happens in parallel, processing multiple possibilities simultaneously. It's like having thousands of linguistic experts collaborating instantly to understand your input and craft a response.
Alignment and Human Feedback
Raw language models can generate problematic content, so Reinforcement Learning from Human Feedback (RLHF) helps align them with human values. Human trainers rate model outputs, and the system learns to prefer responses that humans find helpful, harmless, and honest
Training: Same Principles, Massive Scale
LLMs train using the same fundamental principles we discussed earlier—forward passes, backpropagation, and gradient descent. The difference is scale: instead of our simple house-price network with a few parameters, modern LLMs have billions of parameters and train on vast text datasets from the internet.
Bringing It All Together: From Transformers to ChatGPT
ChatGPT's "GPT" stands for Generative Pre-trained Transformer—a streamlined version of the transformer architecture we just explored. Instead of learning from carefully paired input-output examples, GPT employs unsupervised learning on massive text datasets, simply trying to predict the next word in billions of sentences. This deceptively simple approach—essentially playing an enormous "fill-in-the-blank" game—proved remarkably effective at developing sophisticated language understanding, contextual reasoning, and conversational abilities.
Below example, should help with making the above explanation more easier to understand
Training Phase: Imagine GPT encounters this text during training:
"The Eiffel Tower is located in Paris, the capital of France. This iconic iron structure was built in 1889 and attracts millions of visitors each year. When tourists visit Paris, they often..."
The Learning Process: GPT doesn't see the complete sentence. Instead, it plays "guess the next word":
- Sees: "The Eiffel Tower is located in" → Predicts: "Paris"
- Sees: "Paris, the capital of" → Predicts: "France"
- Sees: "When tourists visit Paris, they often" → Predicts: "visit"
What GPT Actually Learns: By doing this billions of times across different texts, GPT accidentally learns:
- Facts: Eiffel Tower is in Paris, Paris is in France
- Relationships: Tourists visit landmarks
- Language patterns: "capital of [country]" structure
- Context: "iconic" suggests something famous
Real Conversation Result: Later, when you ask: "What should I see in Paris?"
GPT uses all this accumulated knowledge:
- Remembers Eiffel Tower is in Paris (from training)
- Knows it's iconic and attracts visitors (from training)
- Understands you're asking for recommendations (language patterns)
- Responds: "You should definitely visit the Eiffel Tower, it's an iconic landmark..."
The Magic: GPT never explicitly learned "how to give travel advice." It just got really good at predicting what text should come next, and that skill somehow includes helpful, contextual responses!
What once seemed like magical "black boxes" are simply sophisticated pattern-recognition systems built on the same basic principles we explored—neural networks learn through repetition and adjustment. The AI tools you use daily, from ChatGPT to image generators, all share this foundation: they've just gotten remarkably good at recognizing and generating patterns that feel almost human. Understanding these fundamentals transforms AI from mysterious sorcery into impressive but comprehensible science.
References

Author's note: AI was used as a writing assistant to help refine language and improve clarity throughout this post.
